Geld is macht

Geld is macht, al zo lang als er menselijke geschiedenis wordt geschreven. Democratie is één van de vele pogingen om de macht aan het geld te ontnemen. Dat is een gevecht dat nooit ophoudt. Rome had een begin van democratie; maar Crassus en Pompeius, oud-generaals die steenrijk waren geworden van hun rooftochten, hielpen Julius Caesar in het zadel die de Romeinse republiek de nekslag gaf. Enzovoorts. In de VS proberen plutocraten op allerlei manieren het politieke proces te beïnvloeden. Ook via de rechterlijke macht. ProPublica heeft nu een gedetailleerd verhaal over Clarence Thomas, één van de negen leden van de Supreme Court, zeg maar de Hoge Raad. Die liet zich 20 jaar lang feteren door miljardair Harlan Crow. Vluchten in de privéjet, vakanties in het landgoed in de Adirondacks, bootreizen op het privé-jacht. Thomas heeft nooit deze cadeaus geregistreerd. De rechters worden voor het leven benoemd, om ze te beschermen tegen corruptie.
Agitprop
Het Russische Ministerie van Defensie geeft aan alle soldaten een boekje dat ze moet inspireren om te vechten. Daarin de bekende geschiedvervalsing over Oekraïne. Maar meest frappant: er staan zinnen in die regelrecht lijken te zijn gekopieerd uit Josef Stalin’s beruchte ‘bevel nr 227,’ uit de zomer van 1942. Dat was toen het Russische leger, na een paar grote nederlagen, door de Nazi’s werd teruggedrongen tot Stalingrad (nu Volgograd). ‘Geen stap meer achteruit, kameraden!’ stond daar in. In het boekje van najaar 2022 staat: ‘Geen stap meer achteruit! Dat moet nu onze belangrijkste boodschap zijn.’ Stalin, 1942: ‘Alarmisten en lafaards moeten ter plekke worden uitgeroeid.’ Rusland, 2022: ‘Ieder van ons heeft de verantwoordelijkheid om elke blijk van lafheid of paniek hardhandig aan te pakken.’ Zo zijn er meer voorbeelden.
Letland voerde deze week de militaire dienstplicht weer in. Waarom is dienstplicht, militair of civiel, zo ingewikkeld in Nederland?
History of England
J. van der Velde schrijft: ‘Bedankt voor de podcast-tips. Ik heb er één voor jou: the History of England. Alleen geschikt voor de geduldigen: nu al zo’n 400 afleveringen à 30 – 40 minuten. Ik ben bij 200. Geeft prachtige doorkijkjes in de middeleeuwse wereld van machtspolitiek, hoogmoed en menselijk falen. (Waarom noemde Tuchman haar meesterwerk ook alweer ‘A Distant Mirror’?!). Niet alleen zeer informatief, maar ook zéér vermakelijk dankzij weergaloze Britse humor.
Waar staat GTP-4?
Waar staat dat ding eigenlijk? Kun je er naar kijken? Is het een soort server? Hoe groot dan? Gelukkig was er iemand in Australië die zich dat ook afvroeg. Het antwoord: in West Des Moines, Iowa. Daar staat een datacenter met 285.000 CPU cores, 10.000 GPU’s die aan elkaar gekoppeld zijn tot een supercomputer, die dag en nacht draait. Eigendom van Microsoft, aandeelhouder in OpenAI, gebouwd voor OpenAI, om Kunstmatige Intelligentie te ontwikkelen. (Microsoft heeft nog vier andere datacenters in die stad, bij elkaar 320.000 m2, vier miljard dollar aan investeringen.) Die machines verwerken dus de vragen die worden gesteld door de ontwikkelaars van OpenAI in San Francisco (en na de onthulling, overal ter wereld) en volgens protocollen die steeds worden bijgeschaafd.

(screenshot van YouTube)
Sam Altman (OpenAI)

Interview met Sam Altman (37), mede-richter van OpenAI, door Lex Fridman, prof computerwetenschappen bij MIT. Een gesprek van 2,5 uur tussen gelijkwaardigen.
Wat het meeste opvalt is hoe weinig Altman zegt over de echt enge kanten van AI. We hebben geen idee hoeveel mensen en bedrijven op dit moment werken aan het bouwen van AI-modellen. Maar het zijn er tientallen, honderden, duizenden. Hoe ziet een Islamitische AI er uit? Een Russische? Een Israelische? Een … Chinese? Mensen met slechte bedoelingen zullen hun eigen AI ontwikkelen; misschien aan het werk zetten om disinformatie te verspreiden. Op zijn minst.
Altman heeft geen idee hoe dit onder controle te houden.
Ze praten veel over het andere risico: dat de AI al lerende zich ontwikkelt tot een Artificial General Intelligence (AGI), oftewel een ‘computer’ die slimmer is dan wij, met het risico dat die de mensheid zal uitroeien of knechten. Kunnen we waarborgen dat deze AGI, als hij komt, zal handelen in het belang van de mensheid? Hoe doe je dat? Ook hier heeft Altman geen antwoord op.
Het is fantastisch dat OpenAI zo’n ethisch bedrijf is. Wat een zegen! ‘Publiekelijk fouten maken,’ oftewel failing in public is de leidraad. Mensen laten meekijken. Twijfel is goed. Snel en toch behoedzaam werken: GTP-4 was al klaar vorige zomer, toch hebben ze dit wonder acht maanden voor zichzelf gehouden om te testen op zwakke plekken, voor de onthulling. OpenAI heeft een tweetraps bestuursstructuur waarin de beslissende stem wordt uitgebracht door een stichting zonder winstoogmerk. Dus geld is bij OpenAI geen drijfveer. Maar bij al die andere bedrijven ….
Een paar krenten:
‘Wij begrijpen niet altijd waarom het model dit doet, en niet dat.’ (00:13:33) Heeft GTP-4 kennis of wijsheid? ‘Door al deze kennis te absorberen komt hij op enig moment op een punt waar hij in staat is te redeneren’ (00:15:20)
Het is een verademing om te zien hoe GPT-4 nuance en evenwichtigheid in ere herstelt, zegt Fridman. Als je vraagt ‘Kwam Covid nu uit de natuur of uit een laboratorium?’ dan somt hij alle theorieën voor het een en het ander op, weegt ze op hun merites, en concludeert dat noch de ene, noch de andere stelling veel direct bewijs heeft. (1:52:50)
Heeft een AGI een lichaam nodig, om menselijke intelligentie te kunnen evenaren? (01:10:30)
(ook te beluisteren als podcast, zoek Lex Fridman)
Offensieven
Mick Ryan, gepensioneerd Australisch generaal, is één van de productieve en deskundige schrijvers over de oorlog in Oekraïne. Hij schrijft: het Oekraïense offensief is nabij; het worden meerdere offensieven, in het zuiden en oosten. (En dan wil je ook Kiev extra versterken, denk ik dan.) Dit om de Russen in het ongewisse te laten waar de belangrijkste tegenaanval komt. Het land is bezig drie nieuwe legerkorpsen te vormen (Wikipedia: een korps bestaat uit twee tot vijf divisies, elk 10.000-25.000 man sterk plus ondersteunende diensten. Dus dan gaat het over minimaal 60.000 man en maximaal 375.000.)
Het wordt langzaam en vreselijk moeilijk. Dit zijn de versterkingen die Rusland heeft aangelegd:
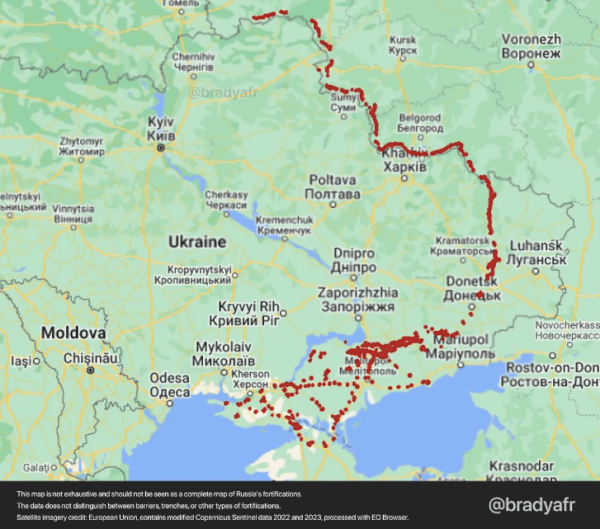
Het verbaast me als niet-soldaat telkens hoe gedetailleerd de artikelen van Ryan en andere ex-soldaten zijn – je zou toch denken dat ze de vijand niet alles aan de neus willen hangen. Maar ik ga er maar van uit dat ze vertellen wat Russen zelf ook kunnen zien met satellieten.
Poetin heft niet gekregen wat hij wilde van Xi. Lawrence Freedman, emeritus prof oorlogskunde aan King’s College in Londen, fileert de gezamenlijke verklaring na de top tussen Poetin en Xi. Die spreekt van ‘alomvattende partnerschap en strategische interactie’ die zich ‘gestaag ontwikkelt.’ “Nou niet precies ‘volle vaart vooruit’,” is het commentaar van Freedman. In februari 2022 spraken de twee nog van een ‘partnerschap zonder beperkingen’, nu wordt de relatie in vage termen besproken, niet als een ‘militair-politiek bondgenootschap’ van ‘confrontationele aard,’ maar als ‘voorkeurspartners.’
“Dit is een partnerschap met beperkingen,” concludeert Freedman.
China zegt ook nergens expliciet dat het de annexatie van Oekraïne steunt of goedkeurt, of afkeurt. De verklaring herhaalt wel de formulering die vaak is gebruikt door wereldleiders, voor het eerst door Gorbachev en Reagan: ‘In een kernoorlog kunnen er geen winnaars zijn, en dus moet die nooit begonnen worden.’ Relevant, nu Poetin kernraketten in Wit-Rusland wil plaatsen, een paar dagen na deze topontmoeting.
Als Poetin ooit richting een wapenstilstand wil, om wat voor reden ook, zal hij waarschijnlijk als eerste Xi bellen, concludeert Freedman. Rusland is de junior partner.
In dit verhaal ook regelmatig links naar bijzondere bronnen. Verslag van een groep van 300 rekruten uit Omsk, waarvan slechts drie overleefden in Zaporizhia. ‘De commandanten beschouwden ze als kanonnenvlees en dwongen ze onder schot tot zelfmoordmissies.’ En naar Mick Ryan, zie hieronder.
Bericht uit China
Dan Wang is iemand die beroepsmatig China bestudeert, voor de – oorspronkelijk Franse – Gavekal groep die research doet voor beleggers. Ieder jaar schrijft hij een terugblik op gebeurtenissen in China. Zeer intelligent, diepe kennis van China, hoogst evenwichtig.
Hier wat fragmenten.Te weinig, maar hopelijk voldoende om u nieuwsgierig te maken naar het hele artikel.
‘Inderdaad was mijn brief van 2021 gericht op China’s sterke punten, vooral het vermogen om zichzelf te vernieuwen. En ik sta nog steeds sympathiek tegenover het beleid van Beijing om bepaalde soorten van groei voorrang te geven boven andere. De weerzin tegen cryptomunten bijvoorbeeld wordt niet ondermijnd door wat we in 2022 hebben gezien. Ik ben net als de overheid niet erg dol op videogames en sociale media. Ik blijf ervan overtuigd dat Beijing makkelijker zijn instituten kan hervormen dan de VS die niet in staat is om iets op te bouwen.’
‘De lange-termijn groeiverwachting voor China werden in 2022 onzeker. Beijing besloot de kant te kiezen van Rusland, een aggressor, terwijl juist in de VS en Europa de afzetmarkten en technologische kennis te vinden zijn. Beijing ziet Rusland als een bondgenoot, die helpt om de wereld te laten zien dat autoritaire regimes bestaansrecht hebben.’
‘Oudere autocraten worden snel nurks. (..) Ik denk dat de partijstaat zal doorgaan met ‘unforced errors’ te maken. Hij heeft immers al veel landen gekwetst met onnodige beledigingen. En is er in geslaagd in het onmogelijke: China’s enorme menselijk kapitaal weg te jagen. China heeft geweldige ondernemers en kunstenaars die de nationale glorie konden brengen waar Xi zo naar smacht. Als ze maar creatief mochten zijn. Iedere middelbare scholier zou een betere propagandist zijn dan het ministerie van Buitenlandse Zaken – als hij maar zijn mond mocht opendoen. Maar er wordt zo veel verprutst door de Marxistisch-Leninisten, die het niet kunnen uitstaan dat er dingen zijn die ze niet onder controle hebben. De partij heeft de afgelopen allerlei groepen van zich vervreemd die gunstig gezind waren: buitenlandse ondernemingen, Europese overheden, artiesten en ondernemers. Ik verwacht dat deze ‘unforced errors’ zullen aanhouden.’
Bill Gates over AI
Hij is net zo overdonderd als iedereen. GTP4 slaagt voor toelatingsexamen biologie studie (‘Dat koos ik omdat de test meer is dan alleen maar feitjes onthouden en reproduceren – je moet ook kritisch kunnen nadenken over biologie’) en geeft ook antwoord op de vraag ‘Wat zeg je tegen een vader met een zoon in het ziekenhuis?’ Daar kwam een bedachtzaam antwoord op ‘dat waarschijnlijk beter was wat de meesten van ons in de kamer hadden kunnen bedenken. De hele ervaring was verbluffend.’
En nu?
Microsoft wil AI integreren in Office. Die kan helpen e-mails te schrijven, de inbox te beheren. Als een soort digitale persoonlijke assistent. Hij onthoudt wat je hebt gelezen, en leest waar je geen zin hebt. Vraag: als de verzekeringsmaatschappij een vraag stelt aan jouw digitale assistent, mag hij die dan beantwoorden zonder jouw toestemming?
Gates ziet AI als een enorme hulp in bedrijfstakken waar te weinig mensen zijn – gezondheidszorg, om maar wat te noemen. Formulieren invullen, verslagjes maken, dossiers bijhouden.
Dit is nog maar het begin. Toch, zegt hij: onze hersenen zijn sloom vergeleken bij een chip. Een elektrisch signaal in onze hersenen beweegt op 1/100.000ste van de snelheid in een chip. Als ze erin slagen om een lerend algoritme te maken dat zo snel werkt als een computer, met een onbeperkt geheugen, heb je een ‘sterke’ AI. Dat kost nog minstens tien jaar, misschien een eeuw. Maar wat dan?
Die sterke AIU’s kunnen hun eigen doelen vaststellen. En wat zouden die zijn? Wat als ze botsen met de belangen van de mensheid?
Maar de doorbraken van de afgelopen maanden komen niet in de buurt van strong AI, zegt Gates (Net als Kevin Kelly, zie de Bickers van vorige week): AI’s hebben geen macht over de fysieke, tastbare wereld en kunnen nog niet zelf hun eigen doelen stellen. (tip R. Leslie)